Accurate prediction of player performance is of immense value to those of use who play fantasy football. With this in mind, I was curious about how well simple prediction models could perform in this context. Conveniently, Sean J. Taylor provided some nice code to make 2017 fantasy football projections which we can use to make 2018 predictions. Looking at his predictions for 2017, I’m not overly optimistic about how the models will perform. At any rate, it ought to be fun to see what theys produce.
My code is mostly identical to Sean’s except I’ve updated some of the year values so that it predicts for the 2018 season and makes use of armchair analysis data from 2017. Since I only changed a few values in the original code to create the analysis datasets, I’ve decided not to display it. However, while running the block of Sean’s code to generate the actual predictions, I encountered some errors having to do with his use of the return() function. Because of this, I’m going to display the code I used to generate the 2018 predictions.
Predictions
The code to generate the predictions is a little tricky, since it uses dplyr’s non standard evaluation (it’s generates them within the do() function). You’ll notice within the if else block of code I’ve removed the return function. The code builds separate models for rushing attempts, passing attempts, receiving yards, etc. for a total of 12 models. The first three metrics, rushing attempts, receiving targets, and passing attempts are the “opportunity” metrics and are modeled using a k-nearest neighbors algorithm. The justification for this that Sean provides is that penalized linear models used for other 9 rate metics would “shrink” the predictions too much (push them toward the average). The ultimate projections for player performance are heavily influenced by the opportunity projections, so it’s very important to get them right.
mySummary <- function(data, lev = NULL, model = NULL) {
out <- c(mean(abs(data$obs - data$pred)),
Evaluation.NDCG(order(data$pred), data$obs))
names(out) <- c('MAE', 'NDCG')
out
}
ctrl <- trainControl(method = 'cv',
number = 10,
summaryFunction = mySummary)
config <- data_frame(metric = c('ra', 'trg', 'pa', 'rec_trg', 'ry_ra', 'tdr_ra', 'tdrec_trg', 'recy_trg', 'py_pa', 'tdp_pa', 'ints_pa', 'fuml_ratrg'),
method = c('kknn', 'kknn', 'kknn', rep('glmnet', 9)),
outcome.metric = c('NDCG', 'NDCG', 'NDCG', rep('RMSE', 9)),
maximize = c(TRUE, TRUE, TRUE, rep(FALSE, 9)),
key = 1)
positions <- data_frame(pos1 = c('WR', 'TE', 'RB', 'QB'), key = 1)
cutoffs <- data_frame(cutoff = 2016:2017, key = 1)
preds <- config %>%
inner_join(positions) %>%
inner_join(cutoffs) %>%
group_by(metric, pos1, cutoff) %>% do({
my.metric <- first(.$metric)
my.pos <- first(.$pos1)
my.cutoff <- first(.$cutoff)
for.reg <- season.metrics %>%
filter(metric == my.metric) %>%
dplyr::select(player, seas, value) %>%
inner_join(features, by = c('player', 'seas')) %>%
filter(pos1 == my.pos) %>%
ungroup()
if (str_detect(my.metric, 'pa') & my.pos != 'QB') {
for.reg$yhat <- 0
for.reg %>% select(player, seas, yhat = yhat)
} else if (str_detect(my.metric, 'trg') & my.pos == 'QB') {
for.reg$yhat <- 0
for.reg %>% select(player, seas, yhat = yhat)
} else if (str_detect(my.metric, 'ra') & my.pos %in% c('TE', 'WR')) {
for.reg$yhat <- 0
for.reg %>% select(player, seas, yhat = yhat)
} else {
X <- model.matrix( ~ 0 + ., for.reg %>% dplyr::select(-player, -value, -pos1))
nzv <- nearZeroVar(X)
X <- X[, -nzv]
y <- with(for.reg, value)
trainable <- !is.na(y) & (for.reg$seas <= my.cutoff)
fit <- train(X[trainable,],y[trainable],
metric = first(.$outcome.metric),
method = first(.$method),
maximize = first(.$maximize),
trControl = ctrl,
preProcess = c("center", "scale"))
for.reg$yhat <- predict(fit, X)
for.reg %>% dplyr::select(player, seas, yhat = yhat)
}
})Rankings based on Predictions
rnks <- preds %>%
spread(metric, yhat) %>%
mutate(py = pa * py_pa,
tdp = pa * tdp_pa,
ints = pa * ints_pa,
rec = trg * rec_trg,
recy = trg * recy_trg,
ry = ra * ry_ra,
td = trg * tdrec_trg+ ra * tdr_ra,
fuml = fuml_ratrg * (ra + pa + trg),
fpts = py / 25
+ recy / 15
+ ry / 10
+ rec * 0.5
+ (td + tdp) * 6
+ ints * -2
+ fuml * -2) %>%
left_join(player %>% select(player, pos1, fname, lname)) %>%
dplyr::select(seas, player, fname, lname, pos1, fpts) %>%
group_by(cutoff, seas, pos1) %>%
arrange(-fpts) %>%
mutate(rnk = row_number())## Joining, by = c("pos1", "player")## Adding missing grouping variables: `cutoff`Running Back Rankings
rnks %>% filter(pos1 == 'RB', seas == 2018, cutoff == 2017) %>%
dplyr::select(player,fname,lname,pos1,fpts,rnk) %>%
.[1:20,] %>% knitr::kable()## Warning: package 'bindrcpp' was built under R version 3.4.4## Adding missing grouping variables: `cutoff`, `seas`| cutoff | seas | player | fname | lname | pos1 | fpts | rnk |
|---|---|---|---|---|---|---|---|
| 2017 | 2018 | LB-0250 | Le’Veon | Bell | RB | 215.4427 | 1 |
| 2017 | 2018 | LF-0650 | Leonard | Fournette | RB | 205.4761 | 2 |
| 2017 | 2018 | DM-4300 | DeMarco | Murray | RB | 203.3259 | 3 |
| 2017 | 2018 | LM-1000 | LeSean | McCoy | RB | 199.9459 | 4 |
| 2017 | 2018 | FG-0200 | Frank | Gore | RB | 180.6542 | 5 |
| 2017 | 2018 | TG-1950 | Todd | Gurley | RB | 177.3315 | 6 |
| 2017 | 2018 | MI-0100 | Mark | Ingram | RB | 171.8154 | 7 |
| 2017 | 2018 | JH-5575 | Jordan | Howard | RB | 158.1608 | 8 |
| 2017 | 2018 | KH-2850 | Kareem | Hunt | RB | 157.1811 | 9 |
| 2017 | 2018 | DF-1875 | Devonta | Freeman | RB | 150.4969 | 10 |
| 2017 | 2018 | CH-5000 | Carlos | Hyde | RB | 150.1606 | 11 |
| 2017 | 2018 | JA-0450 | Jay | Ajayi | RB | 141.6486 | 12 |
| 2017 | 2018 | LM-1150 | Lamar | Miller | RB | 141.0932 | 13 |
| 2017 | 2018 | MG-1150 | Melvin | Gordon | RB | 139.9217 | 14 |
| 2017 | 2018 | IC-0300 | Isaiah | Crowell | RB | 138.7915 | 15 |
| 2017 | 2018 | Ronald Jones II | NA | NA | RB | 133.4248 | 16 |
| 2017 | 2018 | CM-1225 | Christian | McCaffrey | RB | 133.0426 | 17 |
| 2017 | 2018 | LM-1850 | Latavius | Murray | RB | 132.4538 | 18 |
| 2017 | 2018 | MF-1300 | Matt | Forte | RB | 131.4645 | 19 |
| 2017 | 2018 | AK-0050 | Alvin | Kamara | RB | 130.3700 | 20 |
Wide Receiver Rankings
rnks %>% filter(pos1 == 'WR', seas == 2018, cutoff == 2017) %>%
dplyr::select(player,fname,lname,pos1,fpts,rnk) %>%
.[1:20,] %>% knitr::kable()## Adding missing grouping variables: `cutoff`, `seas`| cutoff | seas | player | fname | lname | pos1 | fpts | rnk |
|---|---|---|---|---|---|---|---|
| 2017 | 2018 | JJ-4700 | Julio | Jones | WR | 178.7398 | 1 |
| 2017 | 2018 | AB-3500 | Antonio | Brown | WR | 176.9903 | 2 |
| 2017 | 2018 | LF-0200 | Larry | Fitzgerald | WR | 164.6259 | 3 |
| 2017 | 2018 | ME-0600 | Mike | Evans | WR | 149.0616 | 4 |
| 2017 | 2018 | TH-1850 | Ty | Hilton | WR | 145.0079 | 5 |
| 2017 | 2018 | JL-0215 | Jarvis | Landry | WR | 141.7893 | 6 |
| 2017 | 2018 | RM-1500 | Rishard | Matthews | WR | 138.5234 | 7 |
| 2017 | 2018 | DB-5300 | Dez | Bryant | WR | 132.4038 | 8 |
| 2017 | 2018 | AG-1500 | A.J. | Green | WR | 131.2524 | 9 |
| 2017 | 2018 | GT-0100 | Golden | Tate | WR | 130.7704 | 10 |
| 2017 | 2018 | BC-2325 | Brandin | Cooks | WR | 128.0500 | 11 |
| 2017 | 2018 | DT-0900 | Demaryius | Thomas | WR | 122.2746 | 12 |
| 2017 | 2018 | DH-3950 | DeAndre | Hopkins | WR | 122.2129 | 13 |
| 2017 | 2018 | AT-0350 | Adam | Thielen | WR | 119.4316 | 14 |
| 2017 | 2018 | PG-0100 | Pierre | Garcon | WR | 119.1293 | 15 |
| 2017 | 2018 | MC-2900 | Michael | Crabtree | WR | 118.0380 | 16 |
| 2017 | 2018 | DB-0500 | Doug | Baldwin | WR | 117.1213 | 17 |
| 2017 | 2018 | JS-4750 | Juju | Smith-Schuster | WR | 115.4172 | 18 |
| 2017 | 2018 | CK-1300 | Cooper | Kupp | WR | 115.0892 | 19 |
| 2017 | 2018 | MB-4550 | Martavis | Bryant | WR | 112.0642 | 20 |
Quarterback Rankings
rnks %>% filter(pos1 == 'QB', seas == 2018, cutoff == 2017) %>%
dplyr::select(player,fname,lname,pos1,fpts,rnk) %>%
.[1:20,] %>% knitr::kable()## Adding missing grouping variables: `cutoff`, `seas`| cutoff | seas | player | fname | lname | pos1 | fpts | rnk |
|---|---|---|---|---|---|---|---|
| 2017 | 2018 | CN-0500 | Cam | Newton | QB | 328.2320 | 1 |
| 2017 | 2018 | DB-3800 | Drew | Brees | QB | 326.2442 | 2 |
| 2017 | 2018 | TB-2300 | Tom | Brady | QB | 324.2403 | 3 |
| 2017 | 2018 | MS-4100 | Matthew | Stafford | QB | 323.5988 | 4 |
| 2017 | 2018 | MR-2500 | Matt | Ryan | QB | 323.4057 | 5 |
| 2017 | 2018 | BB-2425 | Blake | Bortles | QB | 319.7643 | 6 |
| 2017 | 2018 | PR-0300 | Philip | Rivers | QB | 318.7249 | 7 |
| 2017 | 2018 | RW-3850 | Russell | Wilson | QB | 311.1636 | 8 |
| 2017 | 2018 | KC-2350 | Kirk | Cousins | QB | 308.0833 | 9 |
| 2017 | 2018 | JG-1850 | Jared | Goff | QB | 293.0441 | 10 |
| 2017 | 2018 | DC-0725 | Derek | Carr | QB | 289.4341 | 11 |
| 2017 | 2018 | DP-2037 | Dak | Prescott | QB | 286.5810 | 12 |
| 2017 | 2018 | EM-0200 | Eli | Manning | QB | 283.5398 | 13 |
| 2017 | 2018 | BR-1100 | Ben | Roethlisberger | QB | 281.3730 | 14 |
| 2017 | 2018 | AD-0100 | Andy | Dalton | QB | 279.9740 | 15 |
| 2017 | 2018 | JF-1900 | Joe | Flacco | QB | 274.1218 | 16 |
| 2017 | 2018 | JC-6200 | Jay | Cutler | QB | 272.2124 | 17 |
| 2017 | 2018 | TT-0500 | Tyrod | Taylor | QB | 267.1779 | 18 |
| 2017 | 2018 | AR-1300 | Aaron | Rodgers | QB | 264.5544 | 19 |
| 2017 | 2018 | CP-0500 | Carson | Palmer | QB | 253.5234 | 20 |
Tight End Rankings
rnks %>% filter(pos1 == 'TE', seas == 2018, cutoff == 2017) %>%
dplyr::select(player,fname,lname,pos1,fpts,rnk) %>%
.[1:20,] %>% knitr::kable()## Adding missing grouping variables: `cutoff`, `seas`| cutoff | seas | player | fname | lname | pos1 | fpts | rnk |
|---|---|---|---|---|---|---|---|
| 2017 | 2018 | TK-0150 | Travis | Kelce | TE | 148.11218 | 1 |
| 2017 | 2018 | JG-2900 | Jimmy | Graham | TE | 137.32173 | 2 |
| 2017 | 2018 | ZE-0100 | Zach | Ertz | TE | 135.75456 | 3 |
| 2017 | 2018 | EE-0400 | Evan | Engram | TE | 134.18324 | 4 |
| 2017 | 2018 | JW-6000 | Jason | Witten | TE | 110.39928 | 5 |
| 2017 | 2018 | KR-1200 | Kyle | Rudolph | TE | 106.56947 | 6 |
| 2017 | 2018 | RG-2200 | Rob | Gronkowski | TE | 101.79246 | 7 |
| 2017 | 2018 | AG-0500 | Antonio | Gates | TE | 101.16792 | 8 |
| 2017 | 2018 | EE-0050 | Eric | Ebron | TE | 90.60055 | 9 |
| 2017 | 2018 | CC-2100 | Charles | Clay | TE | 87.62130 | 10 |
| 2017 | 2018 | HH-0225 | Hunter | Henry | TE | 85.74416 | 11 |
| 2017 | 2018 | JC-4300 | Jared | Cook | TE | 83.79069 | 12 |
| 2017 | 2018 | VD-0100 | Vernon | Davis | TE | 83.44308 | 13 |
| 2017 | 2018 | JD-2550 | Jack | Doyle | TE | 83.36575 | 14 |
| 2017 | 2018 | NO-0150 | Nick | O’Leary | TE | 77.43070 | 15 |
| 2017 | 2018 | JT-2000 | Julius | Thomas | TE | 73.97472 | 16 |
| 2017 | 2018 | TE-0300 | Tyler | Eifert | TE | 72.50556 | 17 |
| 2017 | 2018 | JR-1150 | Jordan | Reed | TE | 72.44428 | 18 |
| 2017 | 2018 | LK-0200 | Lance | Kendricks | TE | 72.07954 | 19 |
| 2017 | 2018 | OH-0250 | O.J. | Howard | TE | 67.21814 | 20 |
Model Performance Plots
truth <- season.metrics %>%
filter(seas == 2017) %>%
dplyr::select(-career.year, -lst, -avg) %>%
spread(metric, value) %>%
mutate(fpts = py / 25
+ recy / 15
+ ry / 10
+ rec * 0.5
+ (tdr + tdrec + tdp) * 6
+ ints * -2
+ fuml * -2) %>%
arrange(-fpts) %>%
mutate(rnk = row_number())
rnks %>%
filter(cutoff == 2016, seas == 2017) %>%
inner_join(truth %>% dplyr::select(player, seas, fpts.true = fpts)) %>%
ggplot(aes(x = fpts, y = fpts.true)) +
geom_point() +
facet_wrap('pos1', scales = 'free') +
theme_bw() +
geom_abline() +
xlab('Projected Points') +
ylab('Actual Points')## Joining, by = c("seas", "player")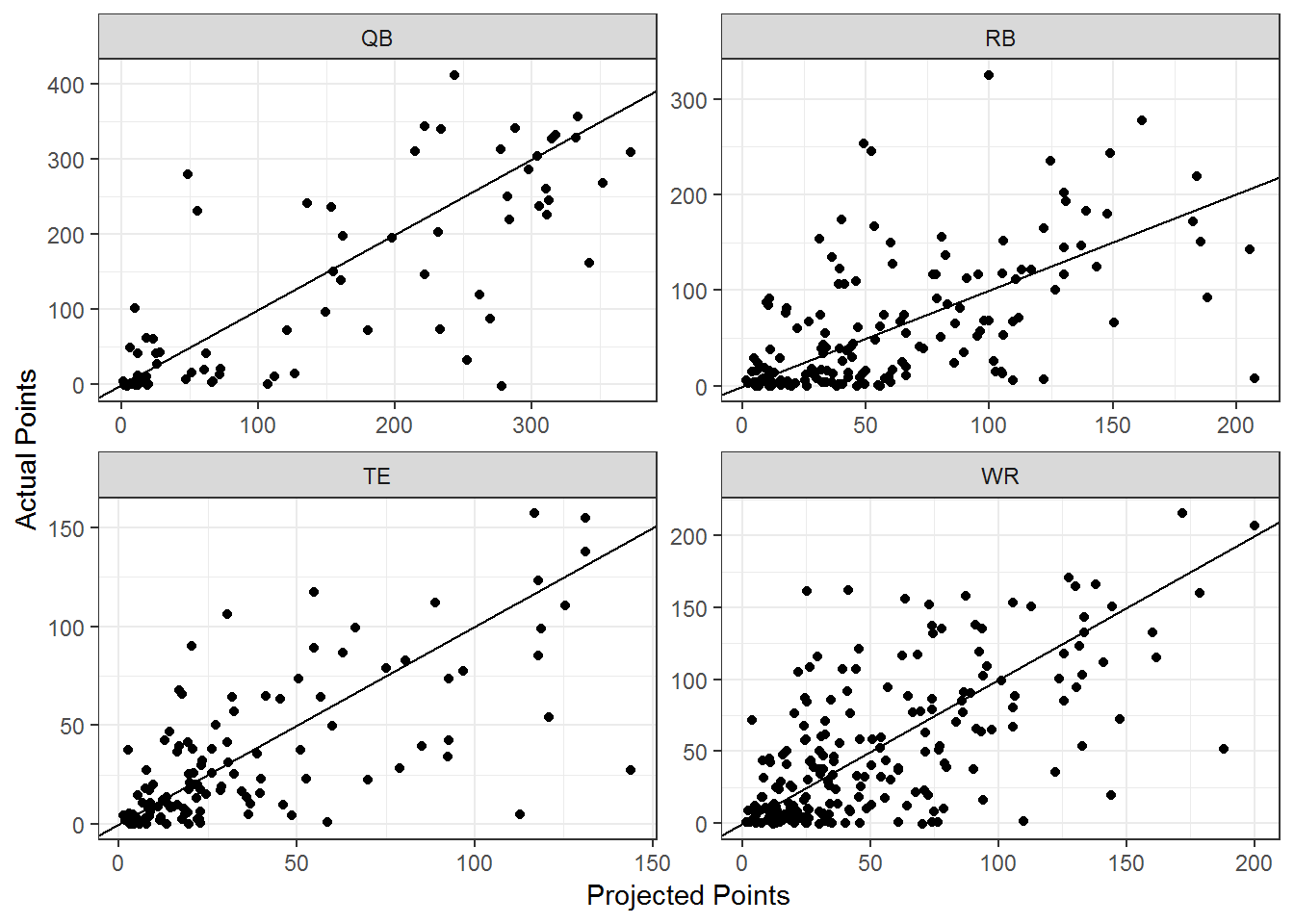
Comments
These predictions do not seem very good at all to me. Looking at the last plot you can see the immense variability about the 45 degree line, some of the estimates are off by very large amounts. This is maybe not surprising when you consider the very limited basis on which the “opportunity” (rushing attempts, etc) projections are made. There is a lot of information that is not captured by previous data. Allowing for smooth functions of the predictors in the rate models would probably improve the performance as well.
Ultimately, in my opinion a better approach to fantasy football player projection is something like what is done at Fantasy Football Analytics. The approach they take is to combine the projections of lots of analysts via some weighting scheme. This would allow the incorporation of a lot more information than the models above, as well as averaging over particular analyst biases.