I studied Economics as an undergraduate and oddly enough I never took a course in econometrics. At the time I was interested in experiments and the experimental design course was offered through the statistics department. So I ended up taking all my methods courses through the statistics department. It all worked out for me in the end, but I’ve always wanted to dedicate some time to properly learning econometrics. Luckily for me an economist friend gave me the book “Mostly Harmless Econometrics” a couple years ago. I’ve finally started reading the book and it’s excellent.
The quality of the book is very high, but there are a few instances of what I would consider not good practice. The one I’m interested in writing about in this post stems from page 18, where the authors’ write “The first question to ask about a randomized experiment is whether the randomization successfully balanced subjects across the different treatment groups”. They then propose that you can answer this question by looking to see whether the differences in pre-treatment covariates are small and non-significant. (Another econometric resource that says to do this is Ben Lambert’s) Graduate Econometrics youtube series. There are a couple problems with this approach.
The whole idea that Randomization has failed if it does not force balance between covariates is, I think, mistaken. If it is not mistaken, then why isn’t randomization pointless since you could forcibly balance or match on observed covariates (why leave it to chance to ruin your trial?). Of course we also care about unobserved covariates as well. However, there are essentially an infinite number of them. The probability that at least 1 has a significant difference across treatment groups must be close to 1 (philosophers have in fact made this argument against randomization). See this John Myles White post for an example where there is always imbalance.
Luckily, balance in this sense doesn’t really matter for valid inference. Instead, what randomization gives us is a probabilistic way to account for the fact that there there will be imbalances. Stephen Senn puts it this way, “It is not necessary for the groups to be balanced. In fact, the probability calculation applied to a clinical trial automatically makes an allowance for the fact that groups will almost certainly be unbalanced, and if one knew that they were balanced, then the calculation that is usually performed would not be correct. Every statistician knows that you should not analyse a matched pairs design as if it were a completely randomised design. In the former, there is deliberate balancing by the device of matching; in the latter, there is not. In other words, not only despite but also because we know that in practice many hidden confounders will be unbalanced, the conventional analysis of randomised trials is valid. If we knew these factors to be balanced, then the conventional analysis would be invalid.” link
In terms of causal effect estimation, which is the primary focus of the Mostly Harmless Econometrics book, randomization makes the treatment assignment conditionally independent of potential outcomes (eliminates selection bias). The authors establish this fact, but then suggest you need to check for balance. But you don’t need balanced treatment groups in terms of observed, or even unobserved, covariates for this to hold.
A separate issue with the suggestion to test balance between treatment groups is that even if this were something you should do, the testing procedure they propose is not a good one. It very obviously suffers from multiple comparison problems. The type I error (false positive rate) associated with multiple testing is bounded by the expression \((1 - (1-\alpha)^m)\), where \(\alpha\) is the significance level of the test, and \(m\) is the number of tests. Below I set up a simple simulation to explore this.
Simulating Type I error from covariate balance checking
Just to give a simple demonstration of the effects of multiple comparison testing on the type I error, I wrote an R function that performs a simulation. The set up is a binary treatment variable with probability of assignment to the treatment group p, X number of covariates that are drawn from a multivariate standard normal with each pairwise correlation randomly generated from a uniform [0,M], where M is the maximum correlation chosen by the user.
For this particular set up, I chose a sample size of 100, treatment assignment probability .5, 10 covariates, a maximum correlation .3, and ran 5000 simulations.
####Checking Randomization simulation
library(MASS)
library(tidyverse)
library(cowplot)
theme_set(theme_bw())
set.seed(9294)
simulation_function <- function(n, p, covariate_num, max_corr, x) {
corr <- ifelse(max_corr == 0,
max_corr,
runif(1,min = 0, max = max_corr))
##Create fake data
##treatment
trt <- rbinom(n, size = 1, p = p)
##covariates: 10 slightly correlated mvn(0,1) distributed variables
mu <- rep(0, covariate_num)
SIGMA <- matrix(corr, nrow = covariate_num, ncol = covariate_num)
#Make diagonal = 1
diag(SIGMA) <- 1
#simulate covariates
covariates <- mvrnorm(n = n, mu = mu, Sigma = SIGMA)
#We know that treatment was randomly assigned independent of covariates
df <- as_tibble(cbind(trt, covariates))
#t-test for covariate; returns p-value
df %>%
gather(-trt, key = covariates, value = value) %>%
group_by(covariates) %>%
nest() %>%
transmute(p_value = map_dbl(data, function(x) {
t.test(x$value[x$trt == 0], x$value[x$trt == 1])$p.value
}),
sim = x)
}
#simulations
sims <- 5000
n <- rep(100, length.out = sims)
p <- rep(.5, length.out = sims)
covariate_num <- rep(10, length.out = sims)
max_corr <- rep(.3, length.out = sims)
param_l <- list(n = n,
p = p,
covariate_num = covariate_num,
max_corr = max_corr,
x = 1:sims)
#simulation results
results <- pmap_dfr(param_l, function(n,p,covariate_num,max_corr, x) {
simulation_function(n = n,
p = p,
covariate_num = covariate_num,
max_corr = max_corr,
x = x)
})
#Proportion of p-values less than .05
p1 <- sum(results$p_value < .05)/nrow(results)
print("Proportion of p-values less than .05")## [1] "Proportion of p-values less than .05"p1## [1] 0.05018#Number of simulations with at least 1 significant p-value
p2<-
results %>%
group_by(sim) %>%
summarize(any_significant = sum(p_value < .05) > 0) %>%
ungroup() %>%
summarize(total = sum(any_significant)/sims) %>%
pull(total)
print("Number of simulations with at least 1 significant p-value")## [1] "Number of simulations with at least 1 significant p-value"p2## [1] 0.3836In this particular simulation, the proportion of total p-values less than .05 was 0.05018, which is close to what we expect. However, the relevant error rate is how many particular simulations produce at least 1 significant p-value and that rate is 0.3836. This number is less than the bound given from the equation above, which for 10 tests give an error rate of about .4. (The bound assumes the tests are independent, but in our case there is correlation so the error rate is lower than the bound.) So you can see that even in a situation where there is no association at all between covariates and treatment groups, checking for balance gives the wrong answer quite often.
The bar plot below shows how many significant p-values were produced for each simulation.
#bar plot
results %>%
group_by(sim) %>%
summarize(number_significant = sum(p_value < .05)) %>%
ggplot(aes(x = sim, y = number_significant)) + geom_bar(stat = "identity")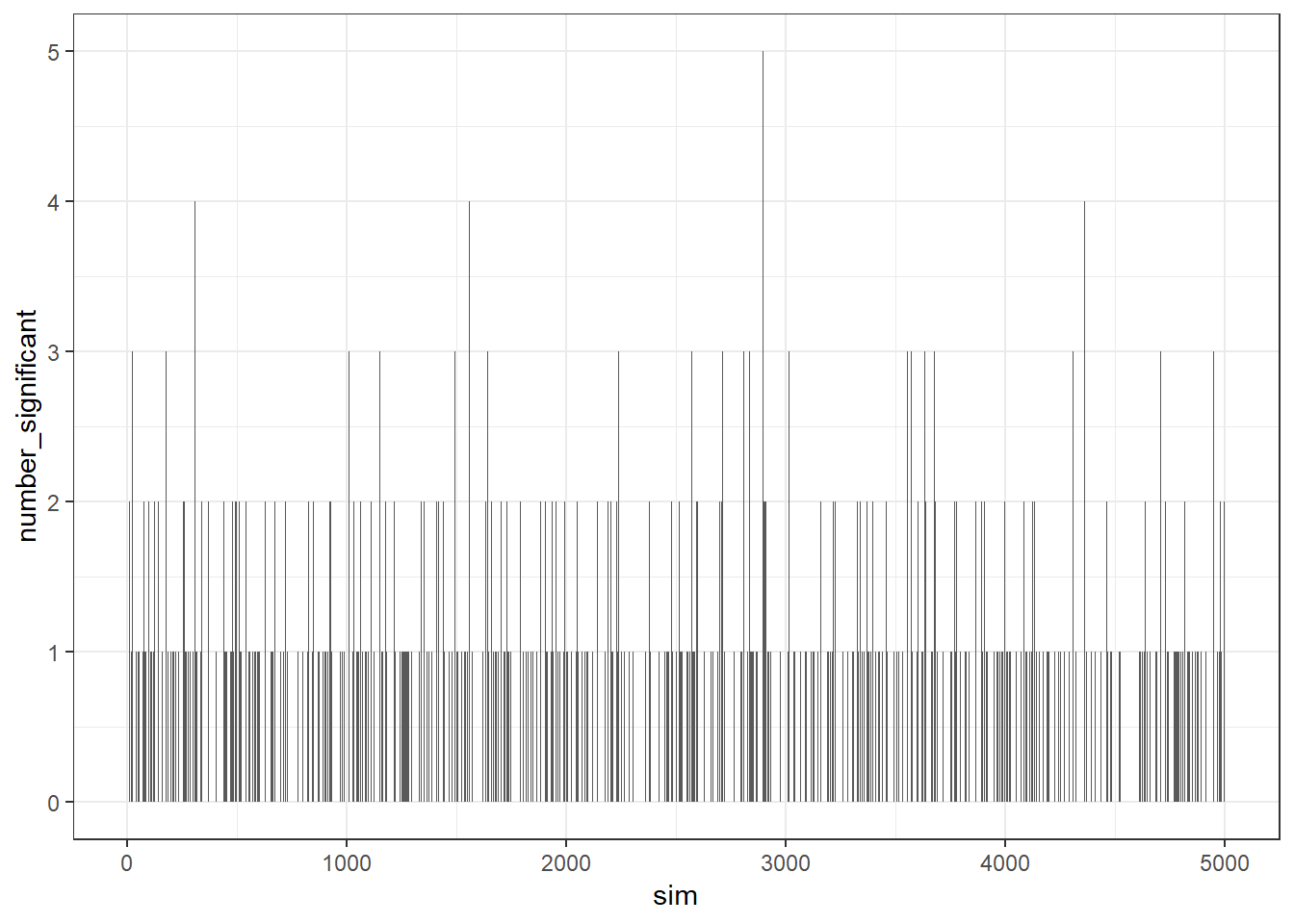
Simulating regression adjustment based on covariate inclusion
A related but separate questionable practice that sometimes occurs in medical studies is to do regression adjustment based on observed covariate imbalances. That is, looking at the dreaded table 1 p-values to determine what covariates to adjust for in your analysis. I think this is also mistaken, but it’s a bit more complicated to show why.
I rewrote the function above function to simulate three simple adjustment scenarios: adjusting for all covariates, adjusting for no covariates, and adjusting for only covariates that are imbalanced between treatment groups. The process that relates the treatment and the covariates to the outcome is a simple one: \[Y_i = 2.5*trt + z_1*\beta_1*x_1 + ... + e_i\]. The beta coefficients are randomly selected from a Uniform(0.1,2). And e_i ~ N(0, 5). Additionally, \(z_i\) is a 1 or 0 generated from a bernoulli distribution with probability of success, \(p2\). Thus, each covariate has probability \(p2\) of having an effect on the outcome. I added this part to imitate the fact that we don’t necessarily know whether a covariate actually affects the outcome. Overall, the process that generates Y is simple, and the only possible misspecification is including variables that don’t affect the outcome (or failing to include those variables).
Below I run 5000 simulations with the same parameter values in the previous run, with the addition of p2 = .7 (the probability each covariate will be included in the process that generates Y).
simulation_function2 <- function(n, p, p2, covariate_num, max_corr, x) {
corr <- ifelse(max_corr == 0,
max_corr,
runif(1, min = 0, max = max_corr))
##Create fake data
##treatment
trt <- rbinom(n, size = 1, p = p)
##covariates: 10 slightly correlated mvn(0,1) distributed variables
mu <- rep(0, covariate_num)
SIGMA <- matrix(corr, nrow = covariate_num, ncol = covariate_num)
#Make diagonal = 1
diag(SIGMA) <- 1
#simulate covariates
covariates <- mvrnorm(n = n, mu = mu, Sigma = SIGMA)
z <- rbinom(covariate_num, size = 1, p = p2)
effects <- runif(covariate_num,0.1,2)
#outcome
Y0 <- 0*2.5 + z*effects%*%t(covariates) + rnorm(n,0,5)
Y1 <- 1*2.5 + Y0
Y <- as.numeric(trt*Y1 + (1 - trt)*Y0)
#Regression with three types of models:
#Adjust for all 10 covariates
#Adjust for no covariates
#Adjust for covariates with significant difference
#We know that treatment was randomly assigned independent of covariates
df <- as_tibble(cbind(Y,trt, covariates))
#t-test for covariate; returns p-value
which_vars <-
df %>%
gather(-Y,-trt, key = covariates, value = value) %>%
group_by(covariates) %>%
nest(-Y) %>%
mutate(p_value = map_lgl(data, function(x) {
t.test(x$value[x$trt == 0], x$value[x$trt == 1])$p.value <= .05
})) %>%
dplyr::select(covariates,p_value)
#model functions
model_func <- function(i, values) {
analysis_df <-
select_at(i,
vars(!!!syms(c(
"Y", "trt",
which_vars$covariates[values]
))))
model <- lm(Y ~ ., data = analysis_df)
#Get treatment estimate and p-value
estimate <- summary(model)$coefficients[["trt","Estimate"]]
p <- summary(model)$coefficients[["trt","Pr(>|t|)"]]
tibble(estimate,p)
}
#Data set of Y, trt, and significant covariates
results_df <-
df %>%
nest() %>%
mutate(
only_sig = map(data, function(i)
model_func(i, which_vars$p_value)),
all_vars = map(data, function(i)
model_func(i, rep(
TRUE, length(which_vars$covariates)
))),
no_vars = map(data,
function(i)
model_func(i, rep(
FALSE, length(which_vars$covariates)
))),
sim = x
)
results_df
}
###Run simulations
sims <- 5000
n <- rep(100, length.out = sims)
p <- rep(.5, length.out = sims)
p2 <- rep(.7, length.out = sims)
covariate_num <- rep(10, length.out = sims)
max_corr <- rep(.3, length.out = sims)
param_l <- list(n = n,
p = p,
p2 = p2,
covariate_num = covariate_num,
max_corr = max_corr,
x = 1:sims)
#simulation results
results2 <- pmap_dfr(param_l, function(n,p,p2,covariate_num,max_corr, x) {
simulation_function2(n = n,
p = p,
p2 = p2,
covariate_num = covariate_num,
max_corr = max_corr,
x = x)
})
sim_results <-
results2 %>%
dplyr::select(-data,-sim) %>%
gather(key = specification, value = result) %>%
group_by(specification) %>%
do({
results2 %>%
dplyr::select(-data,-sim) %>%
gather(key = specification, value = result) %>%
filter(specification == .$specification) %>%
dplyr::select(specification,result) %>%
unnest() %>%
bind_rows()
}) %>%
group_by(specification) %>%
summarize(mu_est = mean(estimate),
var_est = var(estimate),
power = mean(p <= .05))The results of the simulation are summarized in the table below. mu_est is the estimate of the treatment effect, it should be 2.5. var_est is the variance of the estimated mus. And power is the proportion of p-values for the treatment effect that are less than or equal to .05.
knitr::kable(sim_results)| specification | mu_est | var_est | power |
|---|---|---|---|
| all_vars | 2.519668 | 1.425178 | 0.5758 |
| no_vars | 2.524838 | 1.894352 | 0.4736 |
| only_sig | 2.521196 | 1.642270 | 0.4696 |
We can see that pretty much all procedures are unbiased (there may be some simulation error, which is why they are not exactly 2.5), but that only adjusting for covariates that are significantly “imbalanced” has the lowest power. This is related to the fact that if a covariate is imbalanced, then there is some collinearity with the treatment.
Below I plot a histogram of the simulated treatment effect for each procedure.
no_vars <- bind_rows(results2$no_vars)
plot1 <-
no_vars %>%
ggplot(aes(estimate)) +
geom_histogram() +
geom_vline(aes(xintercept =2.5)) +
xlim(c(-2.5,7.5)) +
ggtitle("Distribution of Treatment estimate \n
adjusting for no covariates")
all_vars <- bind_rows(results2$all_vars)
plot2 <-
all_vars %>%
ggplot(aes(estimate)) +
geom_histogram() +
geom_vline(aes(xintercept =2.5)) +
xlim(c(-2.5,7.5)) +
ggtitle("Distribution of Treatment estimate \n
adjusting for all covariates")
only_sig <- bind_rows(results2$only_sig)
plot3 <-
only_sig %>%
ggplot(aes(estimate)) +
geom_histogram() +
geom_vline(aes(xintercept =2.5)) +
xlim(c(-2.5,7.5)) +
ggtitle("Distribution of Treatment estimate \n
adjusting for 'imbalanced' covariates")
cowplot::plot_grid(plot1,plot2,plot3, nrow = 2)## `stat_bin()` using `bins = 30`. Pick better value with `binwidth`.
## `stat_bin()` using `bins = 30`. Pick better value with `binwidth`.
## `stat_bin()` using `bins = 30`. Pick better value with `binwidth`.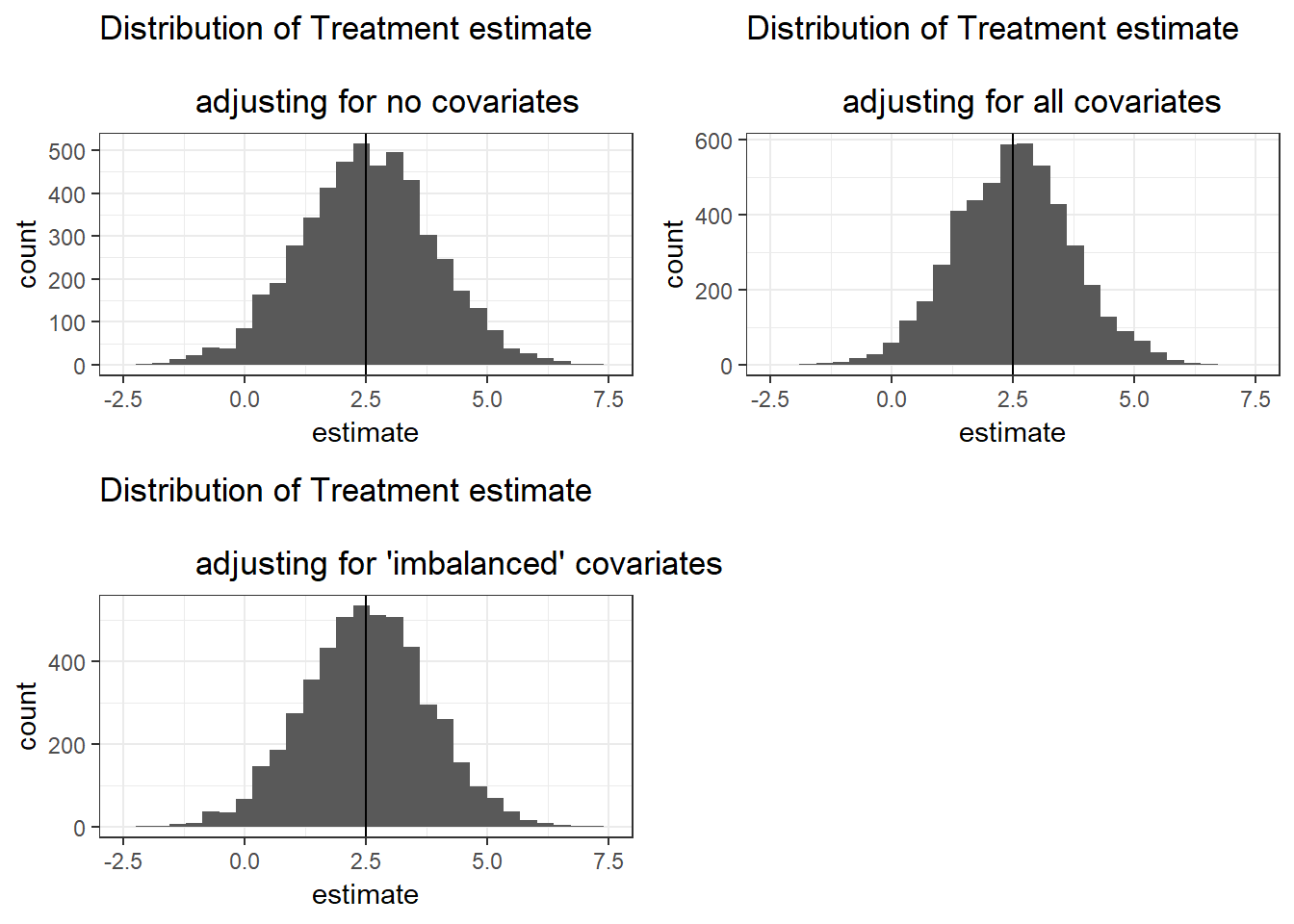
Additional Results
The results above are based on a simulation where on average 70% of the covariates actually affect the outcome. Another interesting set up might be to see how the procedures fair when we change that to 10%.
sims <- 5000
n <- rep(100, length.out = sims)
p <- rep(.5, length.out = sims)
p2 <- rep(.1, length.out = sims)
covariate_num <- rep(10, length.out = sims)
max_corr <- rep(.3, length.out = sims)
param_l <- list(n = n,
p = p,
p2 = p2,
covariate_num = covariate_num,
max_corr = max_corr,
x = 1:sims)
#simulation results
results3 <- pmap_dfr(param_l, function(n,p,p2,covariate_num,max_corr, x) {
simulation_function2(n = n,
p = p,
p2 = p2,
covariate_num = covariate_num,
max_corr = max_corr,
x = x)
})
sim_results3 <-
results3 %>%
dplyr::select(-data,-sim) %>%
gather(key = specification, value = result) %>%
group_by(specification) %>%
do({
results3 %>%
dplyr::select(-data,-sim) %>%
gather(key = specification, value = result) %>%
filter(specification == .$specification) %>%
dplyr::select(specification,result) %>%
unnest() %>%
bind_rows()
}) %>%
group_by(specification) %>%
summarize(mu_est = mean(estimate),
var_est = var(estimate),
power = mean(p < .05))
knitr::kable(sim_results3)| specification | mu_est | var_est | power |
|---|---|---|---|
| all_vars | 2.506699 | 1.253088 | 0.6086 |
| no_vars | 2.505164 | 1.136340 | 0.6502 |
| only_sig | 2.503735 | 1.156623 | 0.6418 |
In this case, it looks like the efficiency gain (in terms of power) disappears if 9 out of 10 covariates included in our model are not actually related to the outcome. But not adjusting at all fairs as well as adjusting only those that are significant.
I think an even more interesting question is how do these results change under greater model mispecification, non-linearity, non-additivity, correlated errors, etc. Maybe that can be the topic of a different post.
Bottom line
Testing covariate balance to check whether your treatment has been successfully randomized is neither conceptually sensible or statistically reliable. You’re better off reading the protocol or talking to the experimenters. Additionally, using covariate imbalance as a means to decide which variables to include in your model tends to reduce the power of your model as compared to adjusting for no covariates or adjusting for all covariates that are thought to affect the outcome. If covariates that affect the outcome are correctly adjusted for in the model, the power of the effect test can be expected to increase.